CaptureBites Metaserver Update: Automated Text Extraction with Azure Form Recognizer
CaptureBites Metaserver introduces a powerful update with its "Extract Text (Azure Form Recognizer)" rule, allowing users to effortlessly extract vital information, including header data, key values, and line items, from various forms such as invoices. This data is then efficiently stored in designated fields. The beauty of this process lies in the utilisation of Azure Form Recognizer's prebuilt models, which eliminate the need for any time-consuming training or configuration.
Here's a breakdown of the key features and benefits of this update:
- Seamless Data Extraction: Users can specify the pages from which they want to extract information. Once the extraction is complete, additional Extract rules can be applied to refine, format, or adjust the values before sending them to the next action.
- Multilingual Support: The Azure Form Recognizer engine, particularly its invoice model, offers support for a range of languages, including English, Spanish, German, French, Italian, Portuguese, and Dutch. It's even worth experimenting with unsupported languages, as satisfactory results have been achieved with Czech invoices, for instance.
- Handling Line Items as Tables: To validate line items as tables with different columns, users can merge all line items into a single field using a Set Field Value rule. The line-item field can then contain all line items in CSV format, enabling structured data management.
- Azure Form Recognizer Service Plans: Users must sign up for the Azure Form Recognizer service. Paid plans for prebuilt models are available, starting at $10 per 1000 pages (S0 Plan for Prebuilt document types). There's also a free 1-year plan (F0) for testing the engine with prebuilt models, allowing up to 500 pages per month for free.
- Speed and Processing: The processing speed differs between the free and paid plans. The free plan has limitations, with only one call allowed every 2 seconds and reading only 2 pages of the invoice. In contrast, the paid plan (S0 plan) offers 15 calls per second, significantly faster and capable of processing all pages of the invoice.
- Pricing Information: Detailed information about pricing plans for the Azure Form Recognizer can be found on the [Microsoft Azure Pricing Page](https://azure.microsoft.com/en-us/pricing/details/form-recognizer/).
- Obtaining Keys: To access the Azure Form Recognizer service, users need to sign up for a key, and instructions for this can be found in the provided documentation.
- Technical Documentation: For deeper technical insights into Microsoft's Azure Form Recognizer engine, including API usage, OCR, data privacy, and security, you can refer to the [Microsoft Azure Form Recognizer documentation](https://docs.microsoft.com/en-us/azure/cost-management-billing/manage/p…).
How to Implement Extract Text (Azure Form Recognizer) in CaptureBites Metaserver:
- Workflow Selection: Users can integrate the "CB – INVOICES, FACTURES, RECHNUNGEN" workflow, which is automatically installed with CaptureBites Metaserver.
- Rule Setup: The Extract Text rules are configured within the MetaServer Extract or Separate Document / Process Page action. Users can add this rule by selecting "Extract -> Text (Azure Form Recognizer)".
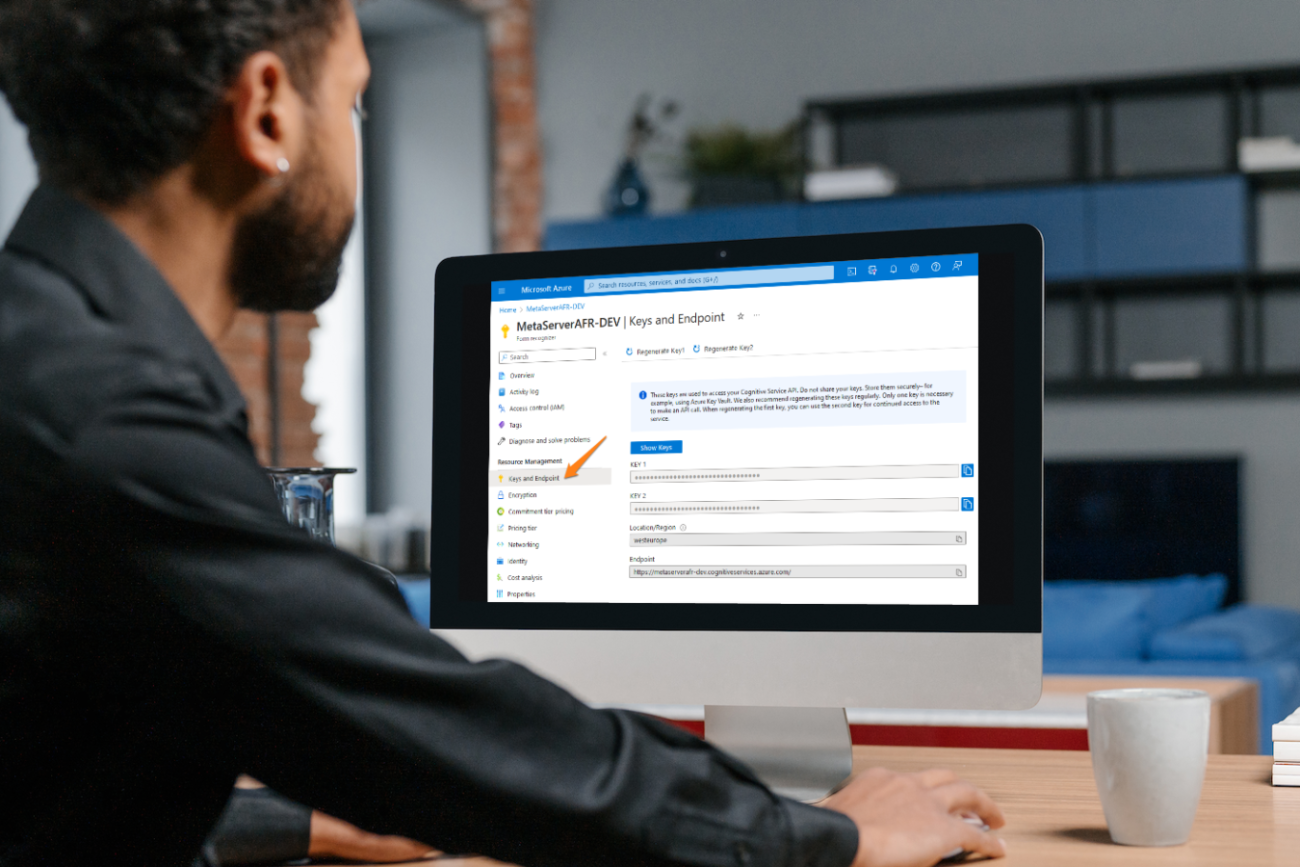
- Key and Endpoint: Setting up the connection to the Azure Form Recognizer resource requires entering the keys, and endpoint, and selecting the location. This information can be obtained from the Microsoft Azure Dashboard.
- Prebuilt Model Selection: Users can choose the appropriate prebuilt model (e.g., Invoice, Receipt, Read) based on their requirements. The Invoice model is especially versatile and can handle various fields and data types.
- API Version: Users can specify the API version for the Azure Form Recognizer, with the option to choose between the preview version or the General Available (GA) version, depending on their Azure Form Recognizer resource location.
- Testing and Confidence: The system allows for thorough testing of the extraction process, including the verification of OCR application and confidence levels. Confidence levels can be adjusted to ensure accurate data extraction.
On-Premise Deployment:
For users with specific security and data governance needs, CaptureBites Metaserver offers the option to run the Azure Form Recognizer engine on-premise using containers through the Docker engine. Detailed instructions for setting up an on-premise Azure Form Recognizer container can be found here.
CaptureBites Metaserver's "Extract Text (Azure Form Recognizer)" update empowers organisations to effortlessly extract and manage critical data from various forms, streamlining processes and enhancing data accuracy and efficiency. With support for multiple languages and flexible pricing options, this update is a valuable addition to any document processing workflow.
For more technical information about the Microsoft Azure Form Recognizer engine and data privacy and security details, please refer to the Microsoft Azure Form Recognizer documentation
Are you ready to simplify your data extraction process? Explore the power of CaptureBites Metaserver's Azure Form Recognizer update today!
